近期,華為AI算法團隊表示在人工智能領域取得顯著突破,研究併發表一種創新的大模型 KV Cache 壓縮算法,稱為「RazorAttention」。
6 i Z( p: B* `, |9 l公仔箱論壇
3 `" j$ q; z& t5 U% c
2 v- _2 i5 _# u' v公仔箱論壇5.39.217.77:8898/ _! k* j# q5 W& G9 O% A9 S
 新算法具有卓越的性能表現,可以有效節省高達 70%的大模型推理 RAM 佔用,AI 大模型提供更多的空間,提供強有力的支援。公仔箱論壇! `0 t, ^ O6 M- A! {" G 新算法具有卓越的性能表現,可以有效節省高達 70%的大模型推理 RAM 佔用,AI 大模型提供更多的空間,提供強有力的支援。公仔箱論壇! `0 t, ^ O6 M- A! {" G
 目前相關論文《RazorAttention: Efficient KV Cache Compression Through Retrieval Heads》已被深度學習領域國際頂級會議 ICLR 2025 收錄,可見其重要性。tvb now,tvbnow,bttvb+ M4 M' O0 w5 m; h' N+ C6 X 目前相關論文《RazorAttention: Efficient KV Cache Compression Through Retrieval Heads》已被深度學習領域國際頂級會議 ICLR 2025 收錄,可見其重要性。tvb now,tvbnow,bttvb+ M4 M' O0 w5 m; h' N+ C6 X
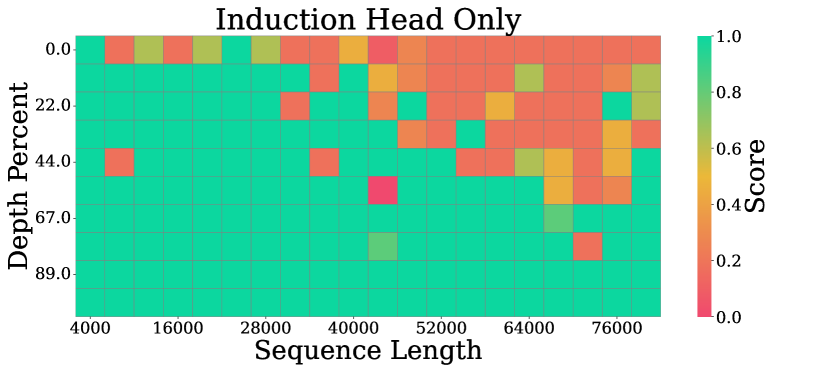
華為表示,RazorAttention 是業界首個基於 Attention 可解釋性的離線靜態 KV Cache 壓縮算法,打破一直以來 AI 大模型長序列 KV Cache 壓縮不理想的硬傷,減少設備負擔,提高計算速度。
! @& l0 i% k: A$ I3 Y5.39.217.77:8898RazorAttention 是通過檢索頭的設定,保證上下文中重要且主要的信息保留,且在保持高精度(誤差小於1%)的前提下,實現靜態有效壓縮最大70% 的 KV Cache RAM 佔用,大大減少 AI 大模型推理的成本。
6 g0 ?, N' w0 M# B+ O0 S( D* I0 r值得一提的是,目前 RazorAttention 算法已實現產品化,並集成在昇騰 MindIE/MindStudio,支援主流 8K~1M 長序列 KV Cache 壓縮,在 32K 以上場景增量吞吐提升20%+。 |




 發表於 2025-1-28 12:28 AM
|
發表於 2025-1-28 12:28 AM
|